Projects
Applications & Models
Implementation of a framework coupling plant, disease and pest models for simulating aphid incidence, density and damage in wheat
Cereal aphids (Hemiptera: Aphididae) are economically important pests in all wheat-producing regions of Brazil. In order to have environmentally friendly control measures, such as biological control, and to reduce the use of insecticides, it is necessary to understand their population dynamics. To this end, the academic community has carried out experiments to develop forecasting models or expert systems to identify the population, growth rates and resulting damage. Computer science offers an effective and efficient way to solve complex problems in agricultural systems, especially in population dynamics. Although these systems are capable of meeting specific needs, much remains to be done to improve a more detailed representation of spatial heterogeneity and its impacts on crops and environmental performance. This work presents a proposal for a framework for coupling simulation models so that they can contribute to the understanding of the interactions between the vector (aphid)-virus-plant pathosystem. By integrating these simulation models, we aim to validate the results with data from field experiments and, from this, assist in the evaluation of the impact of insecticide application on the vector population and determine the incidence of the virus in crops. Click here to see the project’s GitHub repository.
Some information about the project:
Integration project with EMBRAPA and IFSul in which I applied the following knowledge and tools:
The ABISM model was developed with Java.
Data management was done with PostgreSQL.
Use of APIs and JSON files.
It was put into production with Docker.
Coupling with MPI.
spyware
Proof of concept project for developing malware so that we can learn how to prevent and recognize it;
This spyware is part of a larger project called Remote-Analyzer, which is a system developed by me to collect suspicious data from corporate and/or institutional computers. Thus, serving as a more efficient monitoring of the assets of these entities;
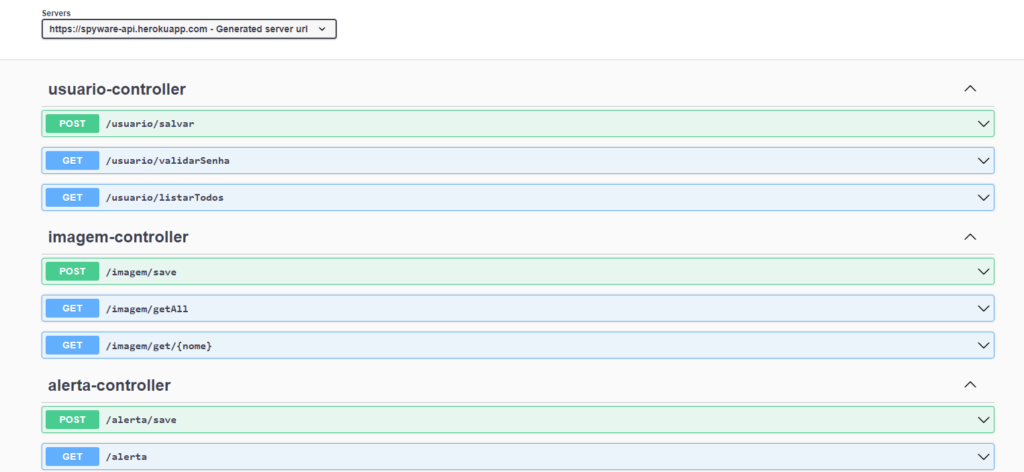
This script that collects the data was developed in Python using several specific libraries to assist in the development. This script is active and will generate an Alert every time something suspicious is typed, sending the data to the API Gateway. The data collected is: the PC’s MAC address, the typed phrase that generated the Alert, the active processes in the system and a PrintScreen of the user’s screen. After that, the script logs into the API Gateway and uses the generated token to save the data in the API. The script also has integration with a model created to detect hate speech, developed by me, in addition to a Sniffer and a Scanner, to avoid unwanted websites and vulnerabilities. Recently, an integration with ChatGPT was made to assist in the analysis of hate speech. Click here to see the project’s GitHub repository. Click here to see the project’s API repository on Heroku. Link to the Swagger interface for the API. Update, the API is no longer available, due to the end of the Free version of Heroku. API documentation made in Postman. The complete application containing all configured microservices can be obtained on DockerHub.






trAI Bot – Crypto Bot
trAI is a Micro-SaaS platform for managing, executing, and monitoring automated cryptocurrency trading strategies. It offers deep integration with Binance (Spot and Futures), custom strategy creation, real-time execution tracking, notifications, and a full-featured dashboard for operational control.
Click here to see the project’s GitHub repository.

versionaAe
versionaAe is a version control system project written in Python using only parsing and System libraries. Click here to see the project’s GitHub repository.
HealthCheck Analytics Platform
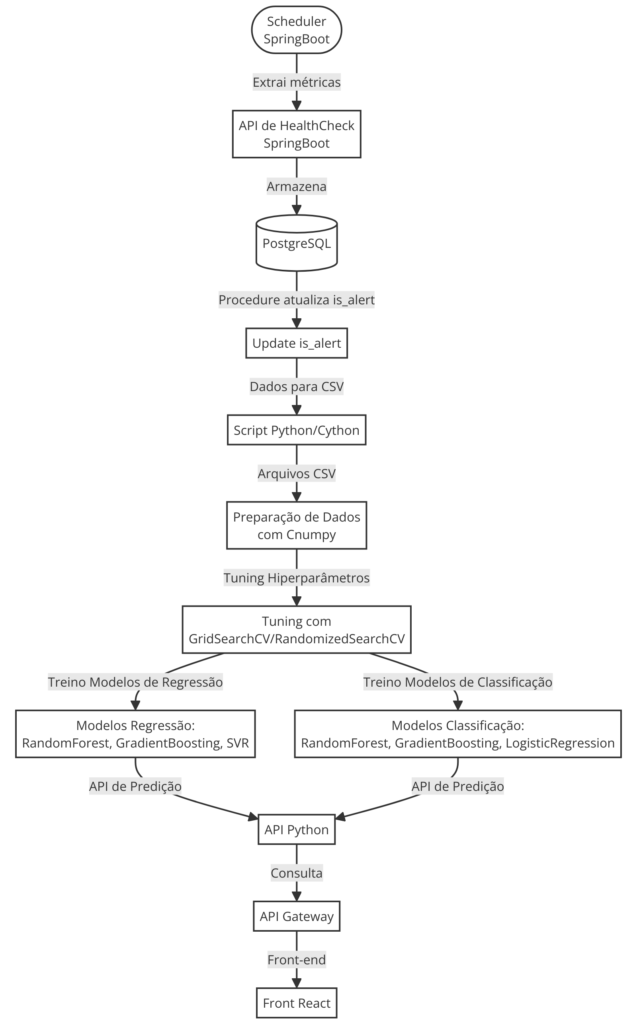
The HealthCheck Analytics Platform is a comprehensive solution for monitoring and analyzing API health metrics. This project uses a microservices architecture to collect, analyze, and predict health metrics, enabling early identification of issues and performance optimization. The system consists of several main components:
HealthCheck Collector API:
Extracts metrics from another API every 15 minutes, storing the results in a PostgreSQL database. A procedure is then executed to update an is_alert flag, analyzing whether the record is outside the expected pattern.
Data Processing Scripts:
Includes extract_dataset_from_database, optimized with Cython for improved performance, and data_preparation using Cnumpy and Cython for data preparation.
Hyperparameter Tuning and Model Training:
Uses GridSearchCV or RandomizedSearchCV to explore parameter combinations, training regression and classification models for each collected metric.
Prediction API (predict_next_value):
Allows you to predict the value of metrics and the is_alert flag for the next 15 minutes based on the data provided. HealthCheck-gate: A Spring API that acts as an intermediary, processing data, saving records and accuracies in the database and communicating with the prediction API.
HealthCheck Dashboard:
A frontend application in React that displays metrics, prediction results and allows user interaction for data prediction. Click here to see the project’s GitHub repository.
noetzoldOS
Desktop Environment Portfolio, developed in Next.js, Javascript and Typescript. Click here to see the project’s GitHub repository. And Click here to see noetzoldOS.
chatbot-getManga
Project of a Bot used to respond to commands on Whatsapp and Telegram using Node.js and the Venom-bot library. This Bot sends Manga chapters (Comic Books), just send the message /mangabot <chapter number>, and it will return images of each page of the chapter. Click here to see the project’s GitHub repository.





Account Storage
Python program that stores names, emails and passwords. Click here to see the project’s GitHub repository.
api-Relatorio
Proof of concept project for using Spring to create a reporting API. In addition, an interface was created to use the API in a more efficient and well-documented way. It is possible to do all the CRUD of the reports. Java 16 was used as the base language, Spring Framework as the platform, the chosen database was PostgreSQL, the API was deployed on Heroku, and Swagger was used for the API interface. Click here to see the project’s GitHub repository. Link to the Swagger Interface for the API.



Temperature Storage
Project using Arduino MEGA 2560 and a heat sensor. Arduino integration was done with Java using the RXTX library. The database used to store the information was MySQL. Click here to see the project’s GitHub repository.
PhotoOrganizer
Program written in Python using the Pillow and Shutil libraries. Its function is to organize JPG files according to their creation or last modification date. The files are organized recursively, by year, month and day. Click here to see the project’s GitHub repository.
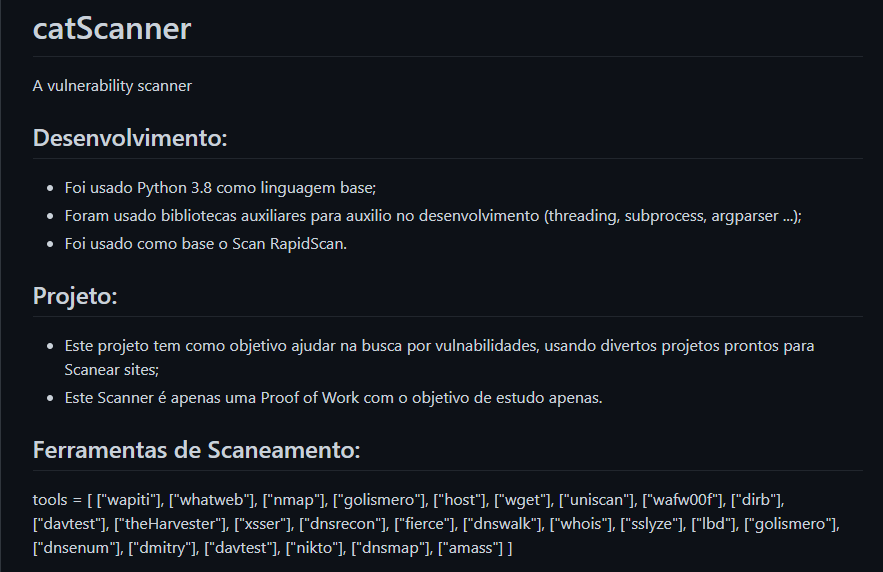
catScanner
This project aims to help in the search for vulnerabilities, using several scripts from famous tools to Scan websites. This Scanner is just a Proof of Work with the objective of studying vulnerabilities and how to identify them, such knowledge can be used in any Web project as prevention of attacks and leaks. Python 3.8 was used as the base language. Auxiliary libraries were used to aid in development (threading, subprocess, argparser …). Scan RapidScan was used as a base. Click here to see the project’s GitHub repository.
API-tester
Java with SpringBoot was used. For security, a token system was implemented as a login. There are individual tests for POST, GET, DELETE and PUT requests. Each request test will be saved in a PostgreSQL database. The project has some features related to request testing. For security testing, there are tests for SQL Injection, Command Injection, XSS Injection, weak passwords and data validation. There is an integration with GPT-3 to check for problems in the API. It is possible to perform performance tests with several parallel requests. It is also possible to automate tests, making the application send several requests to different endpoints. In these automated tests, it is possible to define variables that are fed with the responses of other requests. Click here to see the project’s GitHub repository.
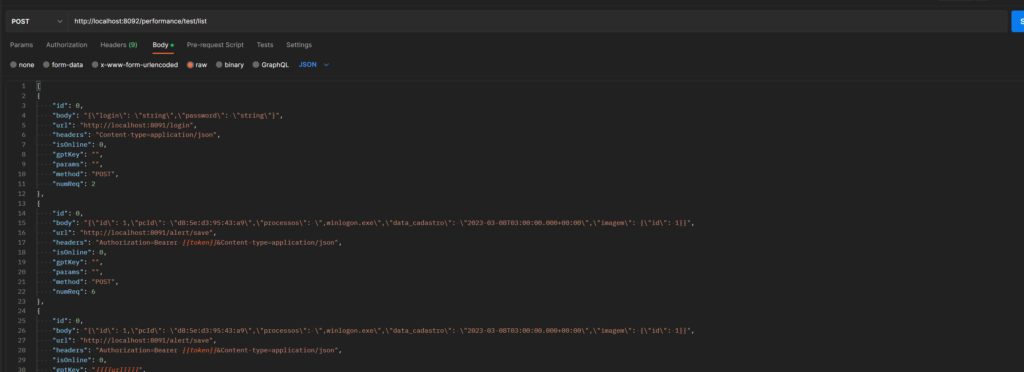
ScriptManager
CLI application, made with Spring Shell for script management. It is possible to add, update, view and remove scripts in different languages. In addition, it is possible to compile the script to validate it. Java 17 was used as the base language. It was developed with Spring Boot. The database used was PostgreSQL. Spring Shell application. The consumption of the Hackereart API for script compilation was done with Feign Client. Click here to see the project’s GitHub repository.
API-LLM
This project is a RESTful API built with Spring Boot that allows you to interact with locally hosted Large Language Models (LLMs) using the Spring AI library. It allows users to send prompts to an LLM server (e.g. Ollama) and receive generated responses in real time. Click here to view the project’s GitHub repository.
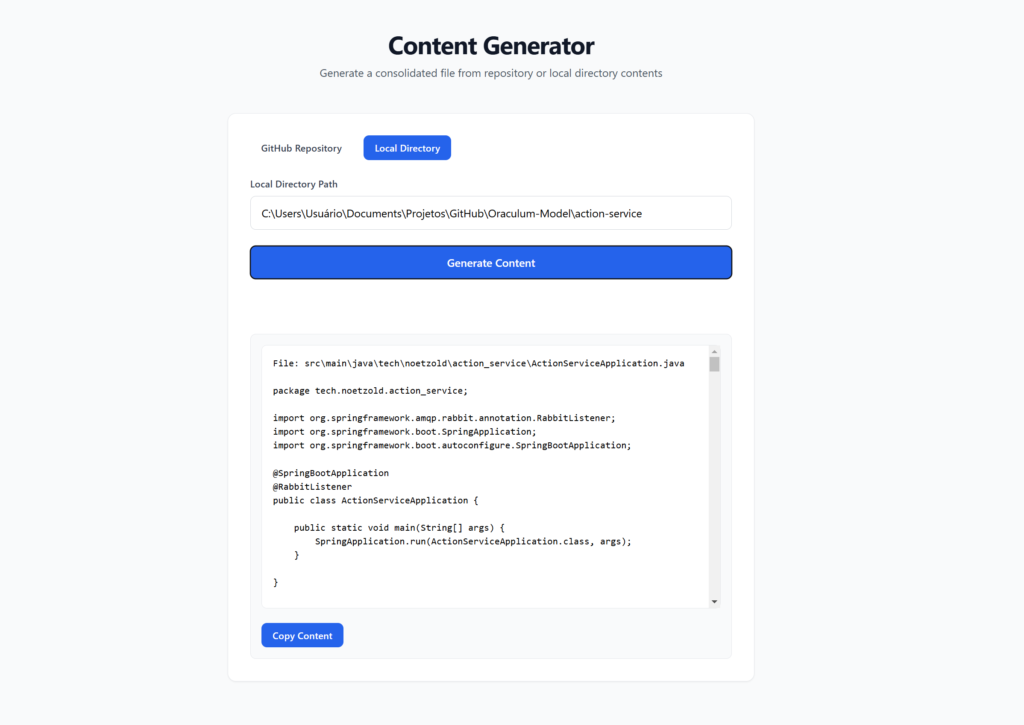
readme-generator
A Spring Boot web application that fetches and concatenates repository content from GitHub. This tool helps developers quickly view and aggregate content from multiple files in a GitHub repository, making it easier to analyze codebases and generate documentation. Click here to see the project’s GitHub repository.
SHiELD – SensorSimulator
The Sensor Simulator SHiELD is a comprehensive architecture for simulating and processing sensor data in real-time, divided into two main components: the Sensor Data Simulator and the Sensor Data Processing Architecture Simulator. The first component allows users to configure sensors and generate predictive data using an ARIMA model through a React-based frontend and backend services built with Flask and Spring Boot. The second component simulates the flow of data within a smart sensor environment, splitting processing into indoor and outdoor stages, with dynamic service balancing, performance metric collection, and intensive data processing handled by native C algorithms. All results are visualized through an interactive metrics dashboard. The system leverages technologies such as RabbitMQ, PostgreSQL, Docker, Java, Python, and React to orchestrate the full end-to-end simulation pipeline. Click here to view the project’s GitHub repository.





WEB APPLICATIONS
complete-ecommerce
An E-commerce built with SpringBoot on the BackEnd and Vue.js on the FrontEnd. The application has well-structured login and security, to save the data an API was used as BackEnd (My application with SpringBoot), which saves in a PostgreSQL database. For payment, Stripe Token was used, with SpringSecurity authentication and authorization were done. All endpoints were mapped and documented by Swagger. The endpoints created in the BackEnd are consumed and fed by the FrontEnd through Vue.js. Use of RabbitMq on the backend to manage queues for product updates. Use of the non-relational database Redis to implement the cache. Testing with JUnit and Mockito. Click here to see the project’s GitHub repository.










Remote-Analyser
A web application made with Spring Framework. This application consumes data from the API Gateway, has authentication through a login and a web interface to view the data. It has three screens, one for login, another for Home (which will load all Alerts, separated by pagination) and a Search screen (which will allow filtering the data by MAC address). Java 1.8 was used as the base language. The database used was PostgreSQL. The login was implemented with Spring Security. The Front-End was made in Thymeleaf. The consumption of the API Gateway was done with Feign Client. The API-Gateway is called spyware-API and its repository can be accessed at this link. This application contains a cache managed by SpringBoot and saved in a noSQL database called Redis, in addition to security based on JWT Tokens also managed by Spring Security. The data is saved in a PostgreSql database and consumed by queues managed by the RabbitMQ messaging service in a scalable way. Click here to see the project’s GitHub repository. The complete application containing all configured microservices can be obtained from DockerHub.
Notes
Full Stack note management web app, using React, Node.js and MongoDB. It has full CRUD functions, adding, removing and editing. It is possible to set a note as a priority. There are filters to look only at notes with priority, normal notes and all. Click here to see the project’s GitHub repository.







reps
Repository and API sharing project. A login in memory and in a database was created. Full CRUD was used to manage the repositories. The site security was done with Spring Security, which manages the logins in memory and in the database. Java 1.8, Thymeleaf 3.0.12, Spring Framework 5.3.7, Spring DevTools, and MariaDB for the database were used. Click here to see the project’s GitHub repository.
Mudi
The project is a store for order control, which are registered and structured with status. These orders have the idea that we have two types of users in the application: The first is the user who will generate offers for the orders that are made and the other user is the one who will register the orders. The Java language (1.8) with Spring Boot was used in the structuring. The data is processed with Spring Data and stored in a MariaDB database. Spring MVC was responsible for the Web part. Styling was done with Thymeleaf and Bootstrap. The login and security system was done with Spring Security. Click here to see the project’s GitHub repository.





Beatmaker
Web application with tabs with sound and visual effects for creating beats. Using Javascript. Click here to see the project’s GitHub.
DApp Game
Proof of concept project for DApp development with token manipulation on a blockchain, the project is just a simple memory game, in which you receive Eth when you find a pair. For testing, a localhost network with the MetaMask wallet was used. Javascript and Solidity were used, the Truffle framework for the development of smart contracts. The local blockchain was configured and managed with Ganache and ERC 721, a standard for NFTs, was also used. And the front end was made in React. Click here to see the project’s GitHub.









IoTManager
Java 17 was used as the base language. It was developed with Spring Boot. The database used was PostgreSQL. Messaging was built with RabbitMQ. Docker was used to configure and deploy the project. Python was used for the script to read the Serial Monitor and send the information to the queues. Two Arduinos were used, an Arduino Uno and a Mega 2560. A C script was loaded onto these Arduinos to capture information from the Sensors. Four sensors were used, two Ultraonic sensors and two Humidity and Temperature sensors. This project aims to test the effectiveness of SpringBoot with RabbitMQ in an IoT application. The goal is to analyze the performance of sending several messages from two different devices. These messages must be consumed and saved in the database, handling errors and mapping failures. In future updates, it is possible to add some functionality to this data, whether viewing or sending this information. Click here to see the project’s GitHub.
Node.js/Express vs NestJs
In order to study and recognize the differences between two of the most famous Node.Js Frameworks (Express and NestJs), I created these two APIs with the same functionalities: a CRUD with a database and authentication via JWT Token. Both APIs use Typescript, MongoDB and Node.js for development, but one with Express and the other using NestJs. The application built with Express has a CRUD of users and endpoints to download videos from YouTube (ytdl-core library), saving the data in a MongoDB database. While the API created with NestJs implements CRUD of tasks and users, saving in the same database. Click here to see the GitHub of the project made with Express and Click here to see the GitHub of the project made with NestJs.




Ruby_Blogstrap
Blog project as a POC for ruby on rails. An in-memory and database login was created. Full CRUD was used for article management. Ruby 3.0.3 was used, Postgresql for the database, Ruby on Rails 2.7, Vagrant was used to virtualize the project and Bootstrap was used for the front-end. Click here to see the project’s GitHub.
Data Science & Machine Learning



")
Hate-Speech-Portuguese
This prediction model is part of a larger project called Remote-Analyzer, which is a system developed by me to collect suspicious data from corporate and/or institutional computers. Thus, serving as a more efficient monitoring of the assets of these entities. This model in Python uses several libraries (pandas, sklearn, nltk and numpy) specific to assist in development. The classifiers were trained with a dataset and exported using pickle. The exported file was imported into an API built with Flask. This API receives, in addition to the classifiers (Logistic Regression, Multinomial Naive Bayes and Linear SVC (SVM)), a body in json through the /predict endpoint, with a sentence to predict whether it is hate speech or not. The input body for the /predict endpoint should be like this: { ‘value’: 0, ‘phrase’: ‘Testing API’ }. The return will be a json like the one shown above, but the ‘value’ will be 0 if it is not hate speech or 1 if it is. Click here to see the project’s GitHub repository.
Wine Quality API
Design of an API with a wine quality prediction model. The API returns the prediction results. Python 3.9 was used with the Pandas, Sklearn, Numpy, Flask and Pickle libraries. Click here to see the project’s GitHub repository, the project’s API can be accessed through this link.



FindWay
Program written in Python using the TKinter and PyGame libraries. It consists of marking two coordinates and creating obstacles, after that you press the space bar and the program will find the closest path connecting the two points, avoiding the obstacles. Click here to see the project’s GitHub repository.
Stroke Prediction API
Stroke prediction model using Python with the Sklearn, Pandas, Pickle, Matplotlib and Numpy libraries. The model is made available through an API built with Flask and hosted on Heroku. Click here to see the project’s GitHub repository, the project’s API can be accessed through this link.

SARS-Cov-2_Classifier
Analysis of data from patients who were tested for SARS-Cov-2. In this analysis, it was first necessary to process the data and obtain the records that contain the data we need. The data used are the Hemoglobin, Leukocytes, Basophils, C-reactive protein mg/dL tests. After that, a decision tree was created and through this tree I discovered which feature was most important, Leukocytes. Click here to see the project’s GitHub repository.




Analytics House Datas
Seattle Real Estate Data, with tables with filters, graphs and histograms of the data. Analysis of various details and with several tools such as pandas, geopandas, streamlit, numpy, datetime among other Python libraries (3.9). The web application was made with streamlit and deployed with Heroku. Click here to see the project’s GitHub repository, the web application can be accessed at this link.
Lotka-Volterra
Project in which I develop two ways to execute a Predator-Prey Simulation Model. The model used was the Lotka-Volterra model. It was developed with Python using the MatplotLib, Numpy and Scipy libraries. Click here to see the project’s GitHub repository.

