Graylog – Gerenciando todos os seus Logs
A melhor forma de entender o funcionamento de um servidor e seus serviços é através da visualização de logs. Desta maneira é possível verificar todos os eventos, erros e avisos que ocorreram em um determinado período de tempo.
Os logs geralmente são separados por tipo, serviço e servidor, como numa árvore. Esta separação faz com que os logs fiquem organizados e facilita uma visão micro, porém dificulta uma visão geral que apresentaria interdependência entre serviços ou consultas rápidas entre diversos servidores.
{kind=link}
Exemplo de estrutura de logs.
Ferramentas como Graylog buscam sanar esta dificuldade ao centralizar os logs, apresentando também funcionalidades que permitem ver histórico, estatísticas e comparativos para identificar e/ou antecipar problemas e necessidades.
Estrutura da Solução
Para garantir um nível alto de disponibilidade da solução de gerenciamento de logs, serão utilizados sete servidores: um com NGINX e HAProxy, três com Graylog e MongoDB, e três com ElasticSearch.
Os servidores utilizados para a confecção deste documento possuem o Sistema Operacional Debian 8 (Jessie).
{kind=link}
Estrutura da solução de gerenciamento de logs com alta disponibilidade.
Configuração Inicial
Para facilitar o apontamento para comunicação entre os servidores, será utilizando nomes DNS que são configurados no arquivo /etc/hosts em cada um dos servidores. Adicione as linhas ao arquivo para que o apontamento seja feito corretamente:
#vim /etc/resolv.conf ... 192.168.0.10 graylog 192.168.0.11 elastic1.graylog 192.168.0.12 elastic2.graylog 192.168.0.13 elastic3.graylog 192.168.0.14 mongo1.graylog 192.168.0.15 mongo2.graylog 192.168.0.16 mongo3.graylog
O host “graylog” é o servidor com NGINX e HAProxy, que servirá de load balancer. Os demais estão com os serviços devidamente apresentados em seu hostname, sendo que os hosts “mongo” também possuem o graylog, como mencionado anteriormente.
Lembre-se de alterar as entradas acima para refletirem seu ambiente.
MongoDB
O MongoDB (ou apenas Mongo) é um serviço de banco de dados NoSQL (que não utiliza SQL, linguagem de pesquisa estruturada). Na solução de gerenciamento de logs com o Graylog, o Mongo é utilizado para armazenar os dados de configuração, como informações de usuário e configuração dos Streams, e não os dados de log.
Para que a alta disponibilidade do MongoDB seja efetiva é necessário ao menos três servidores com o serviço. Por não consumir muito dos recursos do servidor qual está instalado, o Graylog será alocado nos mesmos servidores.
Para saber mais sobre replicação do MongoDB, leia o seu documento oficial.
Instalação do MongoDB
Para instalar a versão estável mais atual do MongoDB (até a publicação deste post), primeiro deve-se adicionar o repositório do Mongo ao gerenciador de pacotes do Debian (apt-get).
Adicione a chave pública utilizada pelo Gerenciador de Pacotes:
# apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 0C49F3730359A14518585931BC711F9BA15703C6
Crie um arquivo com as informações do repositório:
# echo "deb http://repo.mongodb.org/apt/debian jessie/mongodb-org/3.4 main" | tee /etc/apt/sources.list.d/mongodb-org-3.4.list
Atualize o Gerenciador de Pacotes para que ele utilize o repositório do Mongo, podendo assim instalar o pacote:
# apt-get update # apt-get install mongodb-org -y
Iniciando o MongoDB
Antes de iniciar o serviço, edite o arquivo de configuração do Mongo para que ele use autenticação, assim o Graylog possa se comunicar com o usuário criado.
[su_box title=”/etc/mongodb.conf”]security:
authorization: enabled[/su_box]Tendo o serviço instalado no servidor e com o arquivo de configuração editado, devemos iniciá-lo com a opção de Replica Set, que permite os três servidores atuarem como cluster. Esta configuração também diz aos servidores que se o primário falhar, os outros dois devem votar para que um seja eleito como o novo primário.
# mongod --fork --config /etc/mongodb.conf --replSet "rs0"
Explicando cada um dos argumentos utilizados:
—fork: permite que o processo do Mongo não prenda o terminal, sendo executado em segundo plano;
—config: indica o arquivo de configuração que será utilizado;
—replSet: especifica o nome da configuração de replicação.
Configurando a Replicação
Com o serviço iniciado com suporte a replicação nos três servidores, a configuração desta deve ser feita em um, e somente um, dos servidores.
# mongo
rs0:PRIMARY> rs.initiate( {_id : "rs0", members: [ { _id : 0, host : " mongo1.graylog:27017" }] } )
rs0:PRIMARY> rs.add("mongo2.graylog")
rs0:PRIMARY> rs.add("mongo3.graylog")
Para verificar se a replicação foi iniciada corretamente, execute o comando abaixo.
rs0:PRIMARY> rs.status()
Em caso de sucesso, a saída do comando deverá ser semelhante a abaixo.
{
"set" : "rs0",
"date" : ISODate("2017-09-01T20:33:00.474Z"),
"myState" : 2,
"term" : NumberLong(-1),
"syncingTo" : "mongo3.graylog:27017",
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"appliedOpTime" : Timestamp(1504297979, 5),
"durableOpTime" : Timestamp(1504297979, 5)
},
"members" : [
{
"_id" : 0,
"name" : "mongo1.graylog:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 176696,
"optime" : Timestamp(1504297979, 5),
"optimeDate" : ISODate("2017-09-01T20:32:59Z"),
"syncingTo" : "mongo3.graylog:27017",
"configVersion" : 3,
"self" : true
},
{
"_id" : 1,
"name" : "mongo2.graylog:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 176696,
"optime" : Timestamp(1504297977, 3),
"optimeDurable" : Timestamp(1504297977, 3),
"optimeDate" : ISODate("2017-09-01T20:32:57Z"),
"optimeDurableDate" : ISODate("2017-09-01T20:32:57Z"),
"lastHeartbeat" : ISODate("2017-09-01T20:32:58.582Z"),
"lastHeartbeatRecv" : ISODate("2017-09-01T20:33:00.087Z"),
"pingMs" : NumberLong(0),
"electionTime" : Timestamp(1504121266, 1),
"electionDate" : ISODate("2017-08-30T19:27:46Z"),
"configVersion" : 3
},
{
"_id" : 2,
"name" : "mongo3.graylog:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 176696,
"optime" : Timestamp(1504297977, 3),
"optimeDurable" : Timestamp(1504297977, 3),
"optimeDate" : ISODate("2017-09-01T20:32:57Z"),
"optimeDurableDate" : ISODate("2017-09-01T20:32:57Z"),
"lastHeartbeat" : ISODate("2017-09-01T20:32:58.657Z"),
"lastHeartbeatRecv" : ISODate("2017-09-01T20:32:58.772Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "mongo2.graylog:27017",
"configVersion" : 3
}
],
"ok" : 1
}
Crie um base de dados para o Graylog e um usuário para que este possa gerenciá-la.
rs0:PRIMARY> use graylog;
rs0:PRIMARY> db.createUser( { user: "mongo_admin", pwd: "graylog", roles: [ { role: "root", db: "admin" } ] } )
ElasticSearch
O ElasticSearch (ou apenas Elastic) é um engine de busca baseado em Lucene com uma interface web e documentos JSON. Nesta solução ele é responsável pela indexação dos logs recebidos pelo Graylog.
Novamente, para que tenhamos uma alta disponibilidade efetiva, utilizaremos três hosts. A configuração do cluster é simples e garante que todos os nós tenham a mesma informação.
Instalação do ElasticSearch
Como o ElasticSearch é feito em Java, devemos instalar este previamente. Para utilizar a versão mais recente do Elastic é necessário ao menos o Java 8, e este não está no repositório original do Debian Jessie por conta de problemas de licenciamento.
Para instalar o Java 8 facilmente, adicione a linha abaixo no arquivo de repositórios.
[su_box title=”/etc/apt/sources.list”]#Debian 8 “Jessie”
deb http://http.debian.net/debian jessie-backports main[/su_box]
Atualize o Gerenciador de Repositórios e instale o pacote Java.
# apt-get update # apt-get install -t jessie-backports openjdk-8-jdk
Caso tenha problemas para o Java responder em portas IPv4, adicione a variável de ambiente abaixo.
[su_box title=”/root/.bashrc”]export _JAVA_OPTIONS=”-Djava.net.preferIPv4Stack=true”[/su_box]
Tendo instalado o Java, a instalação do ElasticSearch já pode ser iniciada. Para facilitar o processo, crie o diretório onde os índices serão armazenados. Aqui será utilizado o diretório /elastic/4linux, criado no diretório raiz.
# mkdir /elastic/4linux
Importe a chave pública do repositório do Elastic com o comando abaixo.
# wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Adicione as informações do repositório nas configurações do Gerenciador de Pacotes, num arquivo de configuração adicional.
# echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list
Atualize o gerenciador de pacotes e instale o ElasticSearch.
# apt-get update # apt-get -y install elasticsearch
Tendo instalado o Elastic, o usuário do serviço será criado. A partir deste momento podemos alterar o dono do diretório onde os índices serão guardados, dando permissão de gerenciamento para o ElasticSearch.
# chown -R elasticsearch.elasticsearch /elastic/4linux
Configurando o ElasticSearch
A configuração do ElasticSearch é bem simples, necessitando apenas de informações sobre o nome do cluster, diretório de armazenamento, e os servidores do cluster.
Altere o arquivo de configuração do ElasticSearch seguindo o modelo abaixo, alterando as informações para refletirem sua estrutura.
# vim /etc/elasticsearch/elasticsearch.yml
...
cluster.name: 4linux
node.name: ${HOSTNAME}
path.data: /elastic
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elastic1.graylog", "elastic2.graylog", "elastic3.graylog"]
Inicie o ElasticSeach utilizando o systemctl.
# systemctl start elasticsearch.service
Graylog
Como dito no início do post, o Graylog é o centralizador de logs que busca facilitar a busca e compreensão de informações dos serviços, servindo também como ferramenta para identificação e antecipação de problemas. Ele fornece uma interface web e utiliza agents, chamados de Collector-Sidecar, para a coleta e envio dos logs.
Instalação do Graylog
O Graylog não está nos repositórios originais do Debian Jessie, portanto realize o download do pacote de instalação e o instale com os seguintes comandos.
# wget https://packages.graylog2.org/repo/packages/graylog-2.3-repository_latest.deb # sudo dpkg -i graylog-2.3-repository_latest.deb # sudo apt update && sudo apt install graylog-server
Configurando o Graylog
No arquivo de configuração do serviço, localize as linhas abaixo e remova o comentário (se necessário), adicionando as informações de forma que reflita sua estrutura.
OBS: Em apenas um dos hosts deixe a opção “is_master” com o atributo “true”, e altere o endereço HTTP de acordo com o IP do host do Graylog.
is_master = true node_id_file = /etc/graylog/server/node-id password_secret = (VER NOTA1 ABAIXO) root_password_sha2 = (VER NOTA2 ABAIXO) root_timezone = America/Sao_Paulo rest_listen_uri = http://192.168.0.14:9000/api/ web_enable = true web_listen_uri = http://192.168.0.14:9000/ elasticsearch_hosts = http://elastic1.graylog:9200,http://elastic2.graylog:9200,http://elastic3.graylog:9200 elasticsearch_shards = 3 mongodb_uri = mongodb://mongo_admin:graylog@mongo1.graylog:27017,mongo2.graylog:27017,mongo3.graylog:27017/graylog?replicaSet=rs0 rules_file = /etc/graylog/server/rules.drl
Nota1: Para gerar o password, utilize o comando abaixo.
# pwgen -N 1 -s 96
Nota2: Para gerar o password, utilize o comando abaixo.
# echo -n <DIGITE UMA SENHA> | shasum -a 256
Em caso de dúvidas para a configuração do Graylog no modo multi-node, consulte este guia oficial.
Inicie o serviço do Graylog.
# systemctl start graylog-server.service
Você pode acessar a interface web do Graylog entrando na URL especificada em “web_listen_uri”, utilizando o usuário “Admin” e a senha configurada no “root_password_sha2” (Nota2).
Criando Regras Drools
Especificamos na seção anterior um arquivo de regras, no arquivo de configuração do servidor de logs. Este arquivo não é obrigatório, mas regras são úteis para filtrar mensagens enviadas ao servidor antes mesmo que ele as armazene no ElasticSearch.
Neste guia explicaremos como filtrar mensagens com Regex, descartando as mensagens que possuírem a palavra “Debug”.
[su_box title=”/etc/graylog/server/rules.drl”]import org.graylog2.plugin.Message
import java.util.regex.Matcher
import java.util.regex.Pattern
rule “Remove todas as mensagens que nao forem logs de email.”
when
m : Message( message matches “(?!.*Debug.*$” )
then
System.out.println(“DEBUG: Blacklisting message.”); // Don’t do this in production.
m.setFilterOut(true);
end[/su_box]
NGINX
O NGINX é um servidor web que será utilizado como balanceador para as requisições HTTP do Graylog. Sua instalação é bem simples e a configuração possui poucas linhas.
Instalação do NGINX
Para instalar o servidor web, adicione a chave do NGINX.
# curl http://nginx.org/keys/nginx_signing.key | apt-key add -
Atualize o gerenciador de pacotes e instale o NGINX.
# apt-get update # apt-get install nginx
Configurando o Upstream
Edite o arquivo “defaults”, ou crie um novo arquivo de configuração adicional do NGINX, para criar o balanceamento entre os servidores Graylog através de um upstream.
[su_box title=”/etc/nginx/conf.d/default.conf”]upstream graylog {
least_conn;
server mongo1.graylog.:9000;
server mongo2.graylog:9000;
server mongo3.graylog:9000;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://graylog;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
[/su_box]
Em Upstream indicamos os três servidores que serão balanceados e que a forma usada será de o servidor com menor número de conexões receba a mais recente.
Inicie o serviço ou, caso ele já tenha sido iniciado, o reinicie.
# systemctl start nginx.service
HAProxy
O HAProxy serve como um ponto de entrada, recebendo as requisições e as direcionando para os servidores configurados, seja balanceando-as ou não.
Neste guia o utilizaremos para que todas as portas de serviço do Graylog sejam balanceadas entre os três servidores.
Instalação do HAProxy
É possível instalar o HAProxy através dos repositórios originais do Debian Jessie, portanto um único comando é necessário para instalá-lo.
# apt-get install haproxy
Configurando o HAProxy
Adicione ao final do arquivo de configuração do HAProxy as linhas abaixo, que especificam as portas que serão balanceadas entre os servidores.
[su_box title=”/etc/haproxy/haproxy.cfg”]userlist STATSUSERS
group admin users admin
user admin insecure-password password
user stats insecure-password PASSWORD
listen admin_page 0.0.0.0:9600
mode http
stats enable
stats refresh 60s
stats uri /
acl AuthOkay_ReadOnly http_auth(STATSUSERS)
acl AuthOkay_Admin http_auth_group(STATSUSERS) admin
stats http-request auth realm admin_page unless AuthOkay_ReadOnly
#stats admin if AuthOkay_Admin
listen graylog_tcp_9000
bind *:9000
mode tcp
timeout client 120s
timeout server 120s
default-server inter 2s downinter 5s rise 3 fall 2 maxconn 64 maxqueue 128 weight 100
server graylog1 mongo1.graylog:9000 check
server graylog2 mongo2.graylog:9000 check
server graylog3 mongo3.graylog:9000 check
listen beats_output_5044
bind *:5044
mode tcp
timeout client 120s
timeout server 120s
default-server inter 2s downinter 5s rise 3 fall 2 maxconn 64 maxqueue 128 weight 100
server graylog1 mongo1.graylog:5044 check
server graylog2 mongo2.graylog:5044 check
server graylog3 mongo3.graylog:5044 check
[/su_box]
As linhas que possuem a palavra “check” indicam que o HAProxy deve verificar se os servidores especificados estão respondendo na porta informada, evitando assim enviarem requisições para serviços que estão inativos. Por conta disto, a checagem na porta 5044 será apresentada como “sem servidores para resposta” por enquanto, mas isto será corrigido na seção Customização do Graylog: Configuração de Collectors.
Collector-Sidecar
O Collector-Sidecar, ou somente Sidecar, é o agente do Graylog para captura e envio dos logs. Através dele são especificados o servidor para qual os logs serão enviados e os tipos de log que serão monitorados no host.
Instalação do Collector-Sidecar
Neste guia, as coletas de logs serão feitas com o Filebeat. O Sidecar, agente coletor, já possui os binários do Beats em seu pacote.
Para instalá-lo, realize o download do pacote no link do Github e o execute.
# wget https://github.com/Graylog2/collector-sidecar/releases/download/0.1.4/collector-sidecar_0.1.4-1_amd64.deb # dpkg -i collector-sidecar_0.1.4-1_amd64.deb # graylog-collector-sidecar -service install
Edite o arquivo de configuração do Sidecar de forma semelhante às linhas abaixo, para especificar o servidor de logs e os tipos de log que serão monitorados (tags). Pode ser dado qualçquer nome às tags, desde que configurações para estas sejam criadas no Input.
OBS: Modifique o “node_id” para o nome que deseja para este coletor.
[su_box title=”/etc/graylog/collector-sidecar/collector_sidecar.yml”]server_url: http://graylog:9000/api/
update_interval: 10
tls_skip_verify: false
send_status: true
list_log_files:
node_id: graylog-collector-sidecar
collector_id: file:/etc/graylog/collector-sidecar/collector-id
cache_path: /var/cache/graylog/collector-sidecar
log_path: /var/log/graylog/collector-sidecar
log_rotation_time: 86400
log_max_age: 604800
tags:
– linux
backends:
– name: filebeat
enabled: true
binary_path: /usr/bin/filebeat
configuration_path: /etc/graylog/collector-sidecar/generated/filebeat.yml[/su_box]
Especificamos como endereço do Graylog o DNS configurado no arquivo “/etc/hosts”, informando o endereço do servidor NGINX. Como o NGINX está realizando o balanceamento entre os três servidores de log, aquele que tiver o menor número de conexões web receberá o envio dos logs e heartbeat em sua API.
Customização do Graylog
Depois de ter efetuado todas as instalações e configurações acima, é hora de entrar na interface web e começar a monitorar e manipular os logs.
Configurando Collectors
Os logs já estão sendo enviados ao servidor, porém não estão sendo capturados, armazenados e apresentados porque ainda não há configuração de Input. Para criar um vá em System → Inputs.
O Sidecar foi configurado neste guia para enviar os logs utilizando o Beats, portanto o tipo de Input a ser criado deve ser Beats. Selecione-o na página apresentada e clique em “Launch new input.”
Criação de um Input Beats.
Dê um título ao Input e o salve.
Vá até System → Collectors. Se você já configurou algum Collector-Sidecar, verá nesta página que já há algum Collector e, abaixo do nome dele, as tags que foram configuradas no arquivo de configuração do Sidecar. Clique em “Manage Configurations“.
Clique em “Create configuration” para criar uma configuração para uma ou mais tags. Dê um nome à configuração e a salve.
Clique no nome da configuração para editar suas propriedades. Uma página com as configurações de Outputs, Inputs e Snippets será apresentada. Clique em “Create Output“.
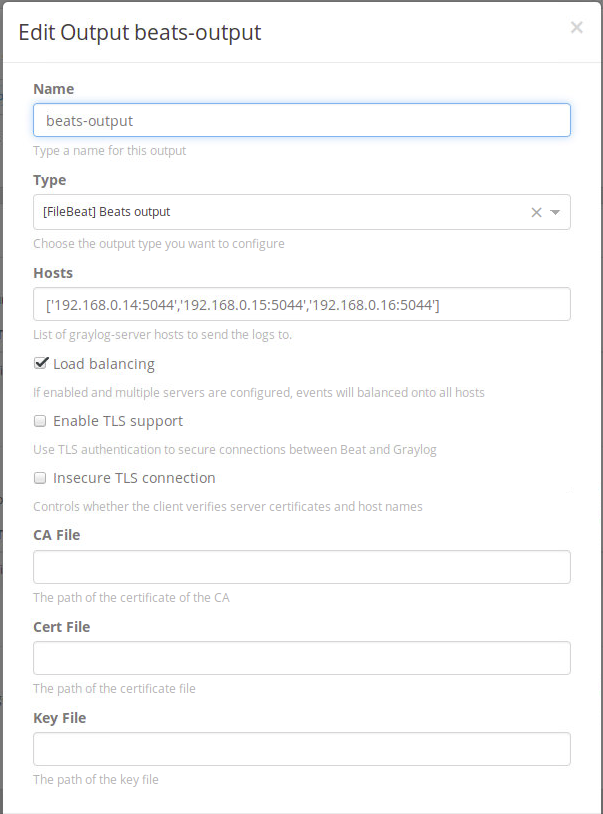
Preencha o nome, coloque o tipo como “[FileBeat] Beats output“, coloque os endereços dos seus servidores Graylog em formato de array, e marque Load balancing.
{kind=link}
Output “beats-output”
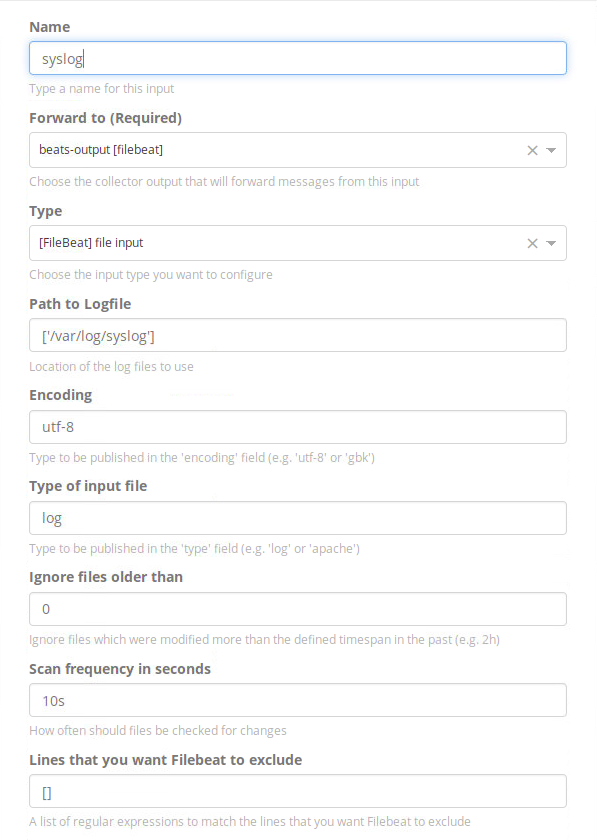
Em seguida, clique em “Create Input” para especificar o que e de qual forma será enviado para o servidor de logs.
{kind=link}
Input Syslog
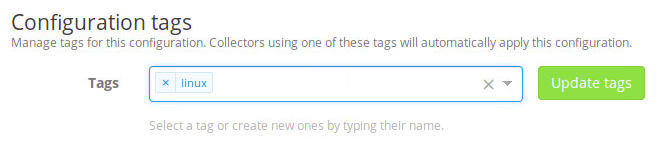
Na parte superior, em “Tags“, preencha quais as tags utilizarão esta configuração de output e input.
{kind=link}
Configuration tags
A partir de agora os arquivos “syslog” dos hosts que possuem o Sidecar com a tag Linux serão monitorados. Para visualizar as mensagens capturadas por este collector, volte em em Systems → Inputs e clique em “Show received messages” no Input criado.
Configurando Extractors
O extractor é um recurso para que campos sejam criados através das mensagens recebidas pelo servidor de logs. Eles facilitam as buscas e possibilitam a criação de gráficos e tabelas.
Os extractors podem ser criados com diversos tipos, entre eles Regex e GROK Filter. Para configurá-los, siga as instruções da documentação oficial do fornecedor neste link.
Criando Gráficos
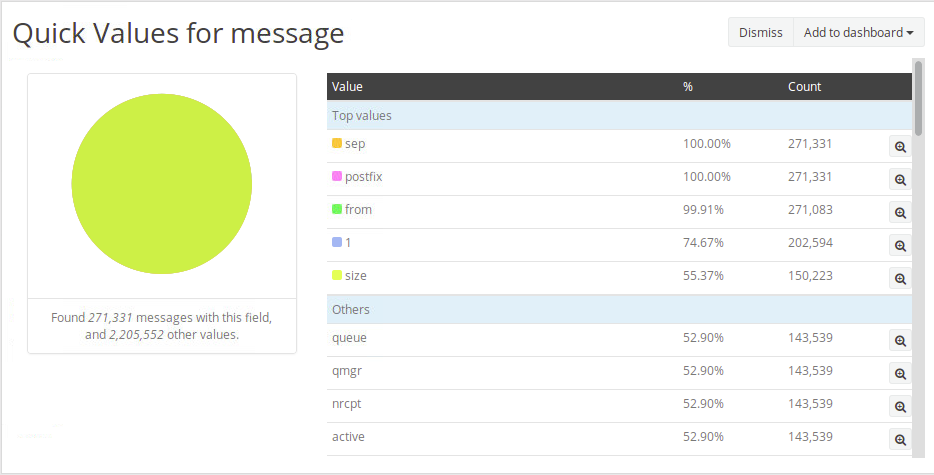
Através de pesquisas na página “Search“, você pode utilizar estatísticas dos campos, padrão ou criados, para gerar gráficos e adicionar ao dashboard.
Para acessar as estatísticas de um campo clique na seta azul ao lado dele, no painel que fica ao lado esquerdo da página.
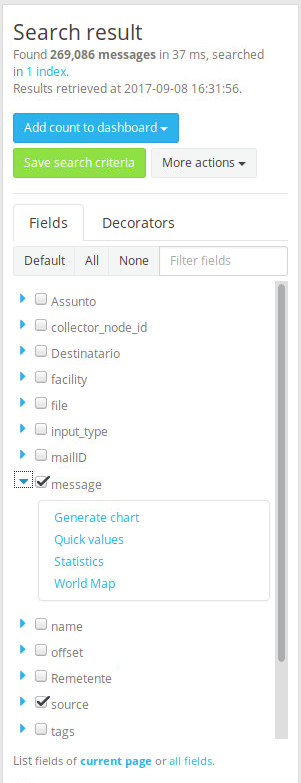
Após clicar em uma das opções, será apresentado um gráfico acima do Histograma. Nele você pode visualizar os dados e adicionar a informação que deseja a um dashboard.
Conclusão
Após seguir todas as instruções deste guia, você já possui um cluster de Graylog em funcionamento com as configurações básicas. Se necessário, as instruções podem ser aplicadas novamente para criações de outras configurações, como novos collectors.
Como todos os softwares livres, a documentação do Graylog, como também do ElasticSearch e do MongoDB estão disponíveis gratuitamente nas páginas de seus fornecedores, e devem ser consultadas antes de qualquer alteração que impacte a infraestrutura ou quando se houver dúvidas.