
Um guia completo para o pré-processamento de dados em machine learning
A bala de prata do pré-processamento para qualquer dataset!
A utilização de técnicas de inteligência artificial para resolver diversos problemas é um processo que em si possui inúmeros etapas que podem ser aplicadas em um ciclo a fim de chegarmos em um resultado satisfatório.
Dentro deste ciclo a etapa pré-processamento talvez seja a mais importante a fim de se obter um bom resultado, o pré-processamento nada mais é do que o processo de preparação, organização e estruturação dos nossos dados além de ser o momento ideal para escolhermos quais dados fazem sentido fazerem parte do nosso dataset.
A ideia deste artigo é ser um ponto de referência para técnicas de pré-processamento que possam ser aplicadas em qualquer tipo de dados que mais tarde serão utilizados em técnicas de classificação com machine learning.
Antes de colocarmos a mão na massa é importante ressaltar a importância desta fase, pois a qualidade dos seus dados pode influenciar diretamente no resultado do seu modelo, muitas das vezes acabamos pensando que o problema da nossa solução é o algoritmo usado para gerar o modelo, porém o grande vilão é o seu próprio conjunto de dados que podem possuir muitos atributos com valores faltantes, outliers e escalas de valores contradizentes e por fim nenhum modelo será capaz de trabalhar com esses dados e gerar resultados de qualidade. Tenha em mente:
A qualidade do resultado do seu modelo começa com a qualidade dos dados que você está “inputando” na etapa de treino!
Para começar vamos importar algumas bibliotecas importantes para esse trabalho. Numpy que irá nos permitir trabalhar de forma eficaz com vetores e matrizes aĺém de facilitar alguns cálculos matemáticos e Pandas que irá nos permitir manipular de forma muito fácil o nosso dataset.
import numpy as np
import pandas as pd
Vamos em seguida carregar o nosso dataset de forma simples com o pandas
dataset = pd.read_csv(‘fake_data_2.csv’)
Para visualizarmos os nossos dados vamos usar a função head que irá nos trazer os 5 primeiros dados do nosso dataset
dataset.head()
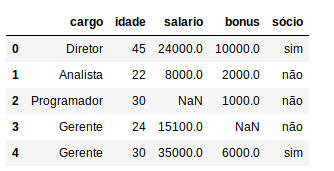
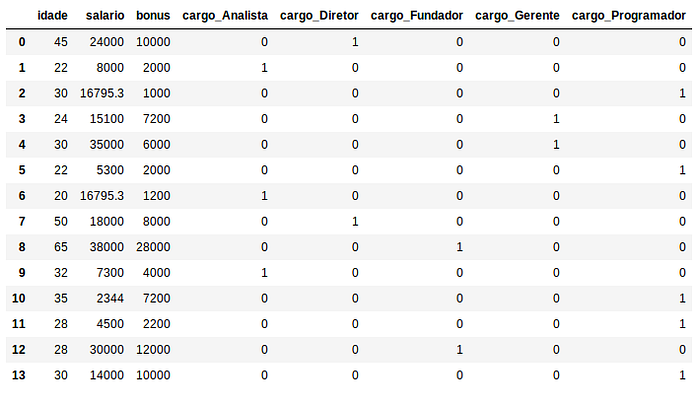
Explicando um pouco melhor o nosso dataset, nós temos os dados de 13 funcionários de uma empresa e baseado no cargo, idade, salário e bônus o nosso modelo futuramente tentará nos dizer quem são os sócios desta empresa.
Agora que conhecemos melhor nossos dados a primeira coisa que devemos fazer é separar os dados em um conjunto de atributos que serão usados como variáveis de input: cargo, idade, salário e bônus e separar a variável resultante: sócio.
X = dataset.iloc[:, :-1].values # cargo, idade, salário e bônus
Y = dataset.iloc[:, 4].values # sócio
Tratando dados faltantes
Show, vamos aos fatos interessantes agora. Como já podemos notar de cara existem alguns dados faltando, como por exemplo o salário e bônus de alguns funcionários. Este problema contém inúmeras formas de ser resolvido e a melhor solução depende muito do seu conjunto de dados e do seu problema, portanto analise a sua situação e escolha a melhor forma de tratar esse problema, talvez a melhor solução nem esteja aqui:
1. Deletar as colunas com dados faltantes: Essa solução ao meu ver é bem drástica e somente deverá ser utilizada quando a variável não exercer uma certa influência no resultado procurado. Talvez seja esta a solução menos recomendada! Mas caso queira utilizá-la basta usar a função dropna pandas, utilizando como parâmetros o axis = 1 para dizer que queremos deletar a coluna e inplace = True para aplicarmos no dataset e não criarmos uma cópia deste:
dataset.dropna(axis=1, inplace=True)
2. Deletar os exemplos com dados faltantes: Uma solução bem melhor para o problema porém ainda não é a ideal para um dataset no qual você possui poucos exemplos, para aplicar basta utilizarmos a função dropna do pandas com o axis = 0:
dataset.dropna(axis=1, inplace=True)
3. Preencher os dados faltantes com a média dos valores do atributo: Essa é a minha solução favorita e que iremos utilizar nesse guia. Em nosso problema iremos fazer isso da forma mais simples, aplicando o valor da média das colunas salário e bônus nos exemplos que não possuem esse valor. Notem que se quiséssemos poderíamos ir um pouco mais afundo e calcular essas médias de acordo com o cargo para depois aplicarmos a média que mais faz sentido. Primeiro vamos voltar ao cabeçalho e importar a classe Imputer que irá nos auxiliar nessa tarefa:
from sklearn.preprocessing import Imputer
Em seguida vamos criar um objeto da classe Imputer:
imputer = Imputer(missing_values = np.nan, strategy = ‘mean’, axis = 0)
Agora vamos aplicar o método fit do imputer apenas nas colunas com dados faltantes:
imputer = imputer.fit(X[:, 2:4])
Por fim vamos aplicar o método transform do imputer apenas nas colunas que precisamos para calcularmos a média e salvarmos em nossa variável X:
X[:, 2:4] = imputer.transform(X[:, 1:3])
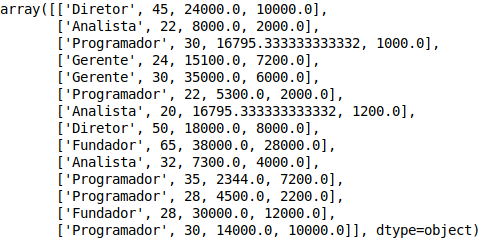
4. Preencher os dados faltantes com o valor que você quiser: Com essa alternativa o céu é o limite e você poderá preencher os seus dados faltantes com o valor que melhor convier para o seu problema, para isto basta utilizar a função fillna do padas, alguns exemplos para o nosso problema seriam:
dataset.fillna(0) #Preencher todos os valores faltantes por zero#Preencher cada coluna com o valor que melhor satisfazer:
values = {'salario': valor, 'bonus': valor}
dataset.fillna(value=values)
Variáveis categóricas
Outro problema do nosso dataset são as variáveis categóricas que nesse caso se restringem apenas a coluna cargo, ou seja, uma variável categórica é uma variável nominal, sem escala, não numérica.
Uma ideia para tratar esse problema é utilizar a classe LabelEncoder do sklearn para transformar os nomes em números (diretor: 0, analista: 1, gerente: 2, programador: 3 e fundador: 4) e por conseguinte transformar esse números em novas colunas do dataset com OneHotEncoder do sklearn, com objetivo de eliminar a hierarquia dos valores que não possuem muito significado para os cargos neste problema. Ou seja os cargos diretor, analista, gerente, programador e fundador seriam colunas do nossa dataset e cada funcionário receberá o valor 1 para o seu cargo na coluna e o valor 0 para os cargos que não ocupam.
Vamos começar importando o LabelEncoder e o OneHotEncoder no cabeçalho:
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
Agora vamos criar um objeto do LabelEncoder e fazer fit_tranform apenas para a nossa coluna com valores categóricos:
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
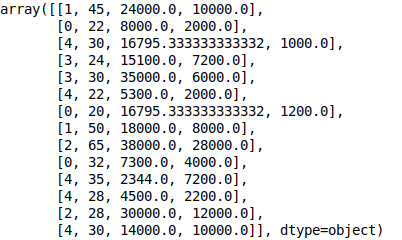
Pronto, já transformamos os nossos valores nominais em numéricos. Podemos notar que os cargos diretor, analista, programador, gerente e fundador são representados respectivamente por 1, 0, 4, 3 e 2. Agora basta transformar esses números em colunas com o OneHotEncoder:
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()

Continuando podemos deixar nossa variável X como um array ou transformar novamente em um dataFrame:
X = pd.DataFrame(np.concatenate(X))
X = pd.DataFrame(X, columns=[‘cargo_diretor’, ‘cargo_analista’, ‘cargo_programador’, ‘cargo_gerente’, ‘cargo_fundador’, ‘idade’, ‘salario’, ‘bonus’])
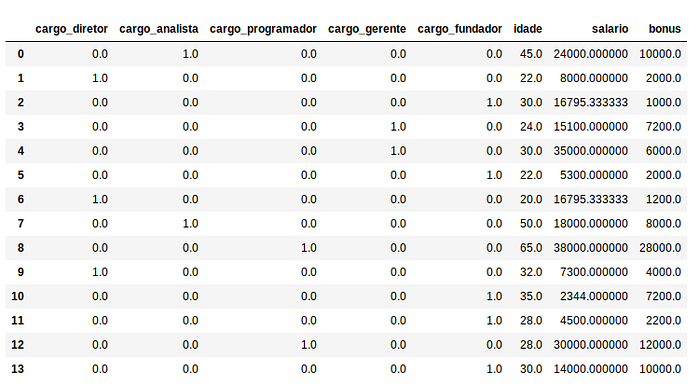
Por fim vamos transformar nossa variável Y com valores categóricos sim e não em valores numéricos, onde teremos 1 para sim e 0 para não:
labelencoder_y = LabelEncoder()
Y = labelencoder_y.fit_transform(y)
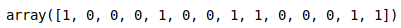
Outra forma de fazermos essa transformação é com o próprio pandas com o método, get_dummies:
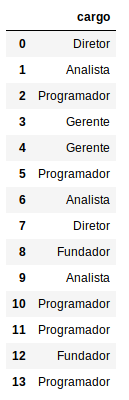
Primeiro vamos criar um dataFrame apenas com a coluna cargos:
X_cargo = pd.DataFrame({‘cargo’:X[:,0]})
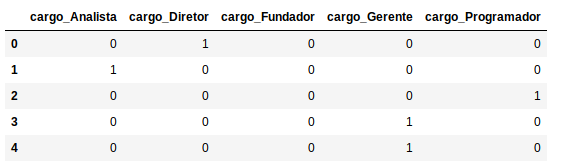
Agora vamos transformar o nosso dataFrame com uma coluna de variáveis categóricas em colunas que representam cada cargo:
X_cargo = pd.get_dummies(X_cargo)
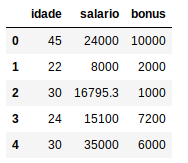
Agora vamos extrair da variável X apenas as colunas com variáveis numéricas e transformar em um dataFrame
X = X[:, 1:]
X = pd.DataFrame({‘idade’:X[:,0], ‘salario’:X[:,1], ‘bonus’:X[:,2]})
Por fim vamos unir as colunas dos cargos ao nosso dataframe X:
X = X.join(X_cargo)
Por conseguinte também vamos transformar a nossa variável Y (é sócio) em valores numéricos, onde sim será 1 e não será zero:
Y = pd.get_dummies(Y)
Y = Y[‘sim’].values
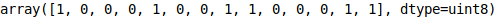
Reescala dos dados
Agora temos um novo problema, você pode observar que os valores das colunas idade, salário e bônus estão em uma escala bem distinta, onde a idade varia entre 20 a 65, salário varia entre 2344 a 38000 e bônus varia entre 1200 a 28000, e isto pode causar um grande problema no treino do nosso modelo uma vez o salário por possuir uma escala muito maior que a idade terá uma influência consequentemente muito maior no resultado e isto não é que nós queremos! Além disso podemos notar que as bordas representam alguns possíveis outliers os quais queremos minimizar o impacto em nossa solução. Para solucionar esses problemas poderíamos usar diversas técnicas de estatística e algumas métricas como quartis, desvio padrão e variância ou podemos ser muito mais espertos e já usar inúmeras ferramentas do sklearn que já aplicam todas essas técnicas a fim de obter uma melhor solução para o nosso problema através da reescala dos dados.
Normalizer
Vamos começar com o Normalizer que talvez seja a solução mais diferente, uma vez que o Normalize age reescalando os dados por exemplos/linhas e não por colunas, ou seja, o Normalizer levará em contas os atributos idade, salário e bonus e reescalar os valores com base nesses três valores. O Normalizer é uma boa escolha quando você sabe que a distribuição dos seus dados não é normal/gaussiana ou quando você não sabe qual é o tipo de distribuição dos seus dados.
from sklearn.preprocessing import Normalizer
X_normalize = X.copy()
X_normalize[[‘idade’, ‘salario’, ‘bonus’]] = Normalizer().fit_transform(X[[‘idade’, ‘salario’, ‘bonus’]])
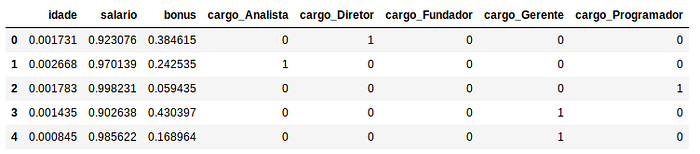
MinMaxScaler
O MinMaxScaler é uma outra alternativa a reescala de dados, seu diferencial se dá uma vez que este age sobre sobre a coluna, ou seja, o cálculo da reescala é feito de forma independente entre cada coluna, de tal forma que a nova escala se dará entre 0 e 1 (ou -1 e 1 se houver valores negativos no dataset). Importante ressaltar que essa técnica funciona melhor se a distribuição dos dados não for normal e se o desvio padrão for pequeno, além disso o MinMaxScaler não reduz de forma eficaz o impacto de outliers e também preserva a distribuição original. De forma simples o MinMaxScaler subtrai o valor em questão pelo menor valor da coluna e então divide pela diferença entre o valor máximo e mínimo:
valor = ( valor — Coluna.min) / (Coluna.max — Coluna.min)
from sklearn.preprocessing import MinMaxScalerX_minMax = X.copy()
X_minMax[[‘idade’, ‘salario’, ‘bonus’]] = MinMaxScaler().fit_transform(X[[‘idade’, ‘salario’, ‘bonus’]])
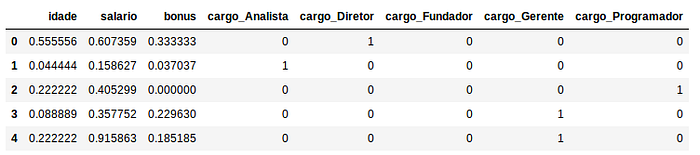
StandardScaler
Assim como o MinMaxScaler o StandardScaler age sobre as colunas, porém seu método é diferente uma vez que este subtrai do valor em questão a média da coluna e divide o resultado pelo desvio padrão. No final temos uma distribuição de dados com desvio padrão igual a 1 e variância de 1 também. Esse método trabalha melhor em dados com distribuição normal porém vale a tentativa para outros tipos de distribuições, além disso podemos deixar como dica que esse método resulta em ótimos frutos quando usado em conjunto com algoritmos como Linear Regression e Logistic Regression.
valor = (valor — média) / desvioPadão
from sklearn.preprocessing import StandardScalerX_standard = X.copy()
X_standard[['idade', 'salario', 'bonus']] = StandardScaler().fit_transform(X[['idade', 'salario', 'bonus']])
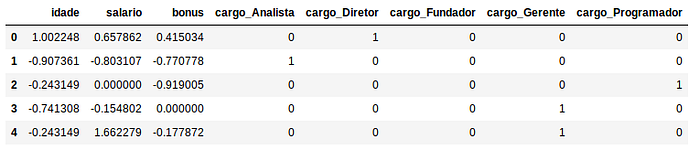
RobustScaler
Também atua sobre as colunas e o diferencial deste método é a combinação com o uso de quartis o que nos garante um bom tratamento dos outliers. Em seu método o RobustScaler subtrai a média do valor em questão e então divide o resultado pelo segundo quartil. Importante notar que os outliers ainda estão presentes porém estão representados dentro de uma escala em que o seu impacto negativo é reduzido.
from sklearn.preprocessing import RobustScalerX_robust = X.copy()
X_robust[[‘idade’, ‘salario’, ‘bonus’]] = RobustScaler().fit_transform(X[[‘idade’, ‘salario’, ‘bonus’]])
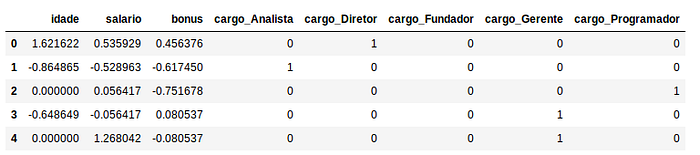
QuantileTransformer
Assim como o RobustScaler atua sobre as colunas e também trata os outliers com uso de quartis. Este método transforma os valores de tal forma que a distribuição tende a se aproximar de uma distribuição normal. Uma observação importante é que essa tranformação pode distorcer as correlações lineares entre as colunas. Neste método todos os valores serão reescalados em um intervalo de 0 a 1 de tal forma que os outliers não poderão mais ser distinguidos logo ao contrário do RobustScaler o impacto da ação em cima dos outilers será grande.
from sklearn.preprocessing import QuantileTransformerX_quantile = X.copy()
X_quantile[[‘idade’, ‘salario’, ‘bonus’]] = QuantileTransformer().fit_transform(X[[‘idade’, ‘salario’, ‘bonus’]])
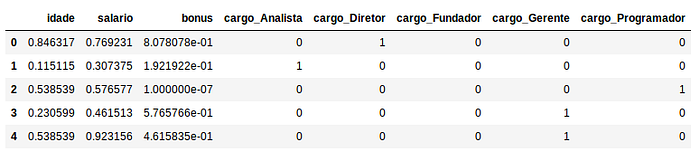
PowerTransformer
Atua sobre as colunas e assim como o Quantile procura transformar os valores em uma distribuição mais normal, sendo indicado em situações onde uma distribuição normal é desejada para os dados, além disso esse método ainda suporta os métodos de transformação
Box-Cox (dataset com dados positivos) e Yeo-Johnson (dataset com dados positivos e negativos).
from sklearn.preprocessing import PowerTransformerX_power = X.copy()
X_power[[‘idade’, ‘salario’, ‘bonus’]] = PowerTransformer().fit_transform(X[[‘idade’, ‘salario’, ‘bonus’]])
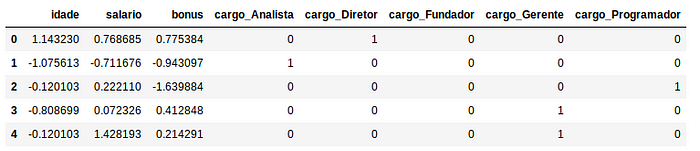
Resumindo as opções de reescala
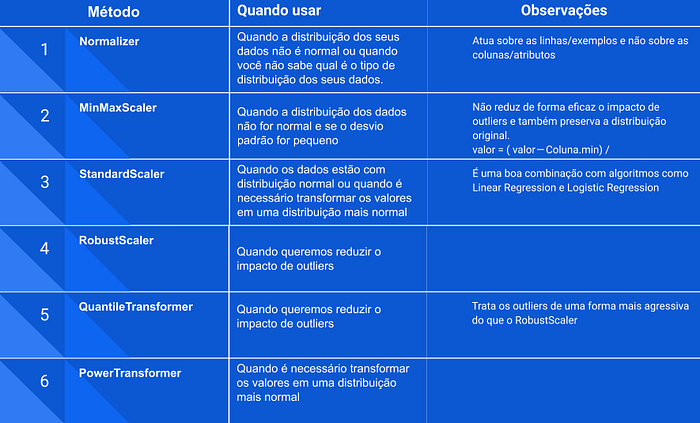
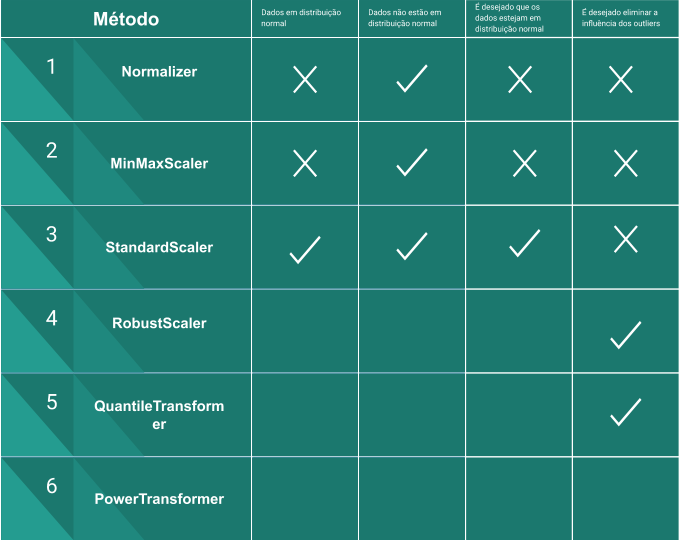
Observação sobre reescala: Não existe uma receita de bolo clara para a escolha da melhor forma de se reescalar os dados, portanto encorajamos que durante a solução do seu problema todas as alternativas acima sejam levadas em consideração e escolhida a forma que apresentar melhores resultados no seu contexto. Importante ressaltar que não se deve aplicar mais de um tipo de transformação ao mesmo tempo, uma vez que isso pode causar em perda total das suas informações originais!
Selecionando os melhores atributos
Agora que temos nossos dados reescalados em alguns datasets podemos contar com muitas colunas/atributos para nos auxiliar na tarefa de predição, porém nem sempre todos esses atributos possuem informações relevantes e muita das vezes podem levar o modelo a ter um resultado inferior do que se tivéssemos usados apenas poucos atributos. Portanto um trabalho importante é selecionar os atributos que mais fazem sentido e agregam valor em nossa solução. Para isso podemos contar com o SelectKBest do sklearn, onde o K representa o número máximo de atributos que desejamos ter em nosso dataset a ser “inputado” em nossa etapa de treino, dado o K o SelectKBest trata de encontrar os K melhores atributos a serem usados. Importante ressaltar que aqui não existe uma melhor maneira de se escolher o valor para K a solução é tentar com diferentes valores e compararmos os resultados. Uma observação importante é que o SelectKBest não suporta dados valores negativos, portanto todos os métodos de reescala que transformam os valores em um intervalo que possui negativos devem ser descartados caso você queira aplica-lo. Em nosso exemplo irei experimentar K = 6 pois possuímos 8 atributos e irei utilizar o método de reescala MinMaxScaler, sinta-se à vontade para experimentar qualquer valor de K e qualquer método de reescala! O método fit_transform já nos retorna os valores dos atributos mais importantes por tanto podemos passar a usar o retorno como o nosso novo X
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2X_new = SelectKBest(chi2, k=6).fit_transform(X_minMax, Y)

Outra forma de escolhermos os melhores atributos é utilizando o SelectFromModel também do sklearn, o diferencial do SelectFromModel se dá na forma como ele escolhe os melhores atributos, uma vez que esta escolha está atrelada a importância de um atributo para um dado modelo, além disso podemos definir um valor limite(threshold) a partir do qual passamos a considerar um atributo como importante. Em nosso exemplo irei atrelar SelectFromModel com o classificador ExtraTreesClassifier. Ainda sobre o valor limite(threshold), podemos passar alguns valores no SelectFromModel ou não(None), caso não seja passado nada o limite utilizado por padrão será 1e-5, também podemos passar uma string “median” onde a média da importância dos atributos será o limite ou ainda podemos passar qualquer valor que desejamos. Aqui irei optar por passar “median”.
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModelclf = ExtraTreesClassifier()
clf = clf.fit(X, y)
clf.feature_importances_ #Mostra a importância de cada atributomodel = SelectFromModel(clf, prefit=True, threshold=”median”)
X_new = model.transform(X_minMax)

Outra opção muito similar ao SelectKBest é o SelectPercentile a diferença se dá que no SelectPercentile iremos passar um atributo chamado percentile que irá selecionar a porcentagem indicada dos melhores atributos, por padrão esse valor é 10. Uma dica importante é que utilizamos o SelectKBest quando temos uma noção da quantidade de atributos que temos e a quantidade de atributos que queremos, já o SelectPercentile é mais utilizado quando não temos uma noção muito clara dos números de atributos.
PCA
Por fim podemos aplicar a técnica PCA nos atributos escolhidos, de forma grossa o PCA nada mais é que uma técnica a qual transforma atributos com uma certa correlação em um único atributo. O PCA deve ser aplicado apenas em casos em que o seu dataset possui muitas colunas, realmente um número muito grande e o treino do seu modelo acaba por ser muito demorado ou inviável devido ao alto número de colunas, uma vez que o PCA é uma técnica na qual sempre haverá perda de informações. Em nosso exemplo o PCA será aplicado de forma meramente ilustrativa uma vez que não possuímos muitas colunas. O atributo n_components representa quantos atributos queremos deixar, outra ideia é utilizar o parâmetro n_components=’mle’ dado isto Minka’s MLE será utilizado para escolher a melhor dimensão a ser mantida no seu caso
from sklearn.decomposition import PCApca = PCA(n_components=’mle’)
X_new = pca.fit_transform(X_minMax)

Separando os seus dados em um conjunto de treino e de teste
Uma das boas práticas no desenvolvimento de modelos é separar o seu dataset um conjunto de treino para treinar o seu modelo e outro de teste para validar os resultados do seu modelo. Essa separação é crucial a fim de identificar se o seu modelo não está “decorando” os resultados ao invés de aprender, o famoso overfitting.
Vamos começar com o método Train Test Split do sklearn
Neste exemplo irei continuar utilizando os atributos da variável X reescalados com o MinMaxScaler. Aqui iremos separar em 4 subconjuntos, X_train com as variáveis de input para treino do modelo e Y_train com os resultados de predição para treino, ambos serão utilizados mais tarde no método fit do seu modelo, X_test com as variáveis de input para test e Y_test com os resultados da predição para testes, o X_test será utilizado no método predict do seu modelo e o Y_test será utilizado para comparar com resultado retornado do seu método predict. O parâmetro test_size serve para indicar que o nosso conjunto de teste terá um tamanho de 20% em relação ao tamanho do dataset e o parâmetro random_state nos permite garantir que a separação dos conjuntos de teste e treino será sempre o mesmo, com a “semente” de aleatoriedade “semeada” sempre no valor indicado.
from sklearn.model_selection import train_test_splitX_train, X_test, Y_train, Y_test = train_test_split(X_minMax, Y, test_size = 0.2, random_state = 0)
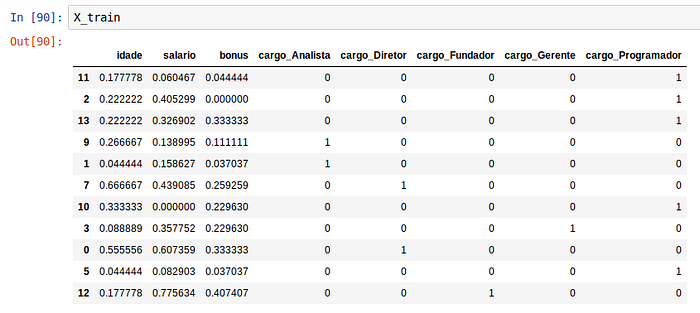
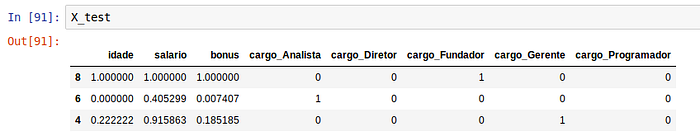
Outra forma de fazemos essa separação é com o KFold do sklearn
Esta é a minha forma favorita de separar o dataset, pois o KFold facilita que possamos separar o nosso conjunto de dadas em conjunto de treinos e teste K vezes (indicado no parâmetro n_splits) e portanto fazer o treino e validar os resultados para 3 conjuntos diferentes de treino e teste. Antes precisamos colocar a nossa variável X em um formato de array.
X_new = X_minMax.valuesfrom sklearn.model_selection import KFoldkf = KFold(n_splits=2)time = 1
for train_index, test_index in kf.split(X_new):
print("K = " + str(time) + " - TRAIN:", train_index, "TEST:",
test_index)
X_train, X_test = X_new[train_index], X_new[test_index]
y_train, y_test = Y[train_index], Y[test_index]
time += 1

Para finalizarmos é importante termos em mente que é de extrema importância que saibamos explorar os parâmetros disponíveis de cada método e classe utilizados no processo de pré-processamento utilizando a documentação do Sklearn que é incrível! Alguns ajustes de parâmetros podem trazer grandes ganhos para a sua solução, porém apenas com testes será possível encontrar os melhores parâmetros pois cada dataset tem suas peculiaridades, assim como cada problema e sua solução!