
Bibliotecas de Data Science
Anaconda

O primeiro passo é baixar o Anaconda. Essa distribuição de Python é indispensável para quem se interessa por ciência de dados, uma vez que lhe dá acesso a poderosas bibliotecas para data science e machine learning. Além disso é gratuita e contém todas as bibliotecas que abordaremos ao longo desse Turing Talks.
Para ter acesso a todo esse conteúdo só precisa seguir o guia de instalação disponível no link: https://www.anaconda.com/distribution/. Fique atento para fazer o download referente ao seu sistema operacional.
Jupyter Notebooks
Uma ferramenta muito utilizada na área de Data Science (e outras) são os Jupyter notebooks.

Eles permitem que você combine código com texto e imagens. Dessa forma, eles podem ser usados, por exemplo, para mostrar uma análise de dados (com explicações, gráficos e outras visualizações) ou ensinar algum assunto para os seus leitores.
Para entender melhor o que é um notebook, veja o exemplo abaixo.https://medium.com/media/19d617ae27c78771eacc3cfd5c8f1ee4
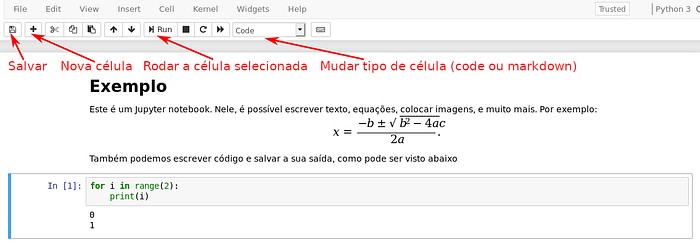
A formatação das células de texto é feita por meio de markdown. Em markdown, a formatação em itálico e negrito é feita utilizando asteriscos: *itálico*, **negrito**. Para escrever o título de uma seção, a linha deve comecar com #. Para mais sobre markdown, veja o link abaixo.
Para utilizar os notebooks, você pode seguir esse tutorial de instalação. Para acessar o jupyter e criar notebooks, basta ir no menu iniciar e abrir o Jupyter Notebook (no Windows) ou rodar o comando
jupyter notebook
no terminal (em qualquer sistema operacional).
Você também pode editar os notebooks no Google Colab e salvá-los no Google Drive. A interface é um pouco diferente da descrita acima, mas a funcionalidade é a mesma.
Mais informações
- Comandos mágicos: https://ipython.org/ipython-doc/3/interactive/magics.html
- Markdown: https://www.ibm.com/support/knowledgecenter/SSQNUZ_current/com.ibm.icpdata.doc/dsx/markd-jupyter.html
Numpy

NumPy (Numerical Python) é a biblioteca que você precisa saber para fazer ciência com seus dados, principalmente porque fornece uma estrutura de dados multidimensional com muitos benefícios em relação às listas de python, como a velocidade das operações em arrays e o menor uso de memória. Isso ocorre porque Numpy é em sua maioria escrita em C, linguagem que faz melhor aproveitamento da arquitetura da sua máquina. Além disso, Numpy fornece diversas operações em arrays (como as de álgebra linear) que facilitam muito a manipulação dessa estrutura de dados.
E como se isso já não fosse suficiente, ela conta com uma quantidade imensa de algoritmos científicos já implementados de forma otimizada, como: transformada discreta de Fourier, simulações estocásticas e muito mais.
Para utilizarmos essa biblioteca, inserimos a seguinte linha de comando no inicio do código e acessamos suas funcionalidades pela abreviação np.
import numpy as np
Como criar uma estrutura de dados (array) Numpy?
Primeiro é necessário importarmos o numpy. Com isso, podemos converter uma lista em um array:https://medium.com/media/200ced1884ea098efdaac61a61d2c73d
Algumas funções elementareshttps://medium.com/media/d58d552fdba86f0b789a7c482c93b16a
Operações básicashttps://medium.com/media/a75eaa023e2a011b4b690b5be8fc7425
Random
Todas as funções do módulo random possuem um argumento size que pode ser uma tupla ou um inteiro que define a dimensão da matriz, ou número de elementos do array.https://medium.com/media/1649d48b547a8c36cb4f69c54cbfb77d
Mais informações
- Documentação Numpy: https://docs.scipy.org/doc/numpy/user/index.html
Pandas

Pandas é a biblioteca de python mais famosa para análise de dados, ela fornece uma performance altamente otimizada, uma vez que seu código fonte é escrito em python, com numpy e linguagem C.
Para utilizarmos essa biblioteca, é necessário inserir a seguinte linha de comando no inicio do código. Acessamos suas funcionalidades pela abreviação pd.
import pandas as pd
Existem dois tipos de estruturas de dados que utilizaremos para manipular os dados inputados: Series e DataFrames.
Series
É uma estrutura de dados unidimensional que armazena valores de uma mesmo tipo (int, float, …) e associado a cada valor existe um índice único.https://medium.com/media/97bd3737ef1809a149d01377ce367071
DataFrame
É uma estrutura de dados análoga a uma tabela com linhas e colunas, em que as colunas têm nomes e as linhas índices.
Em um DataFrame, cada coluna é uma série. Desse modo, podemos pensar que cada linha do DataFrame representa alguma observação (um indivíduo, um objeto, …) e que cada coluna representa uma característica dessa observação. No dataset de flores que veremos abaixo, cada linha representa uma flor e cada coluna representa uma característica dessa flor.
Como criar um DataFrame?
- Listas e Dicionários
Como analisar e visualizar uma DataFrame?
Para responder essa pergunta apresentaremos mais uma forma de criar um DataFrame, que é importando um arquivo csv. Em um arquivo csv, cada linha do arquivo corresponde a uma linha da tabela e as colunas são separadas por vírgulas. O primeiro DataFrame criado acima, em csv, seria:
, A, B, C, D
0, 0.62, 0.82, 0.15, 0.54
1, 0.60, 0.89, 0.62, 0.91
2, 0.58, 0.52, 0.83, 0.32
3, 0.78, 0.85, 0.01, 0.58
Para entender melhor como os DataFrames são utilizados, usaremos como exemplo um dataset muito conhecido pelos cientistas de dados — o Iris (https://archive.ics.uci.edu/ml/datasets/iris). Esse dataset contém algumas informações quantitativas sobre a pétala de três tipos de flores. E esses dados são utilizados para classificar os tipos de flores.https://medium.com/media/aa4d673eee301cc60c4806227cc933f7
- Describe e Info
Como selecionar índices ou colunas?
- Colunas
- Linhas
A principal diferença entre os métodos loc e iloc é que com iloc acessamos somente índices numéricos, mesmo que a indexação de uma DataFrame não seja numérica
Como filtrar uma DataFrame?https://medium.com/media/cbb688641be73d597430ce068fa06fdc
Mais informações
- Tutorial DataFrame: https://www.datacamp.com/community/tutorials/pandas-tutorial-dataframe-python
- Playlist Pandas para Data Science: https://www.youtube.com/watch?v=yzIMircGU5I&list=PL5-da3qGB5ICCsgW1MxlZ0Hq8LL5U3u9y
Matplotlib

Para utilizar a biblioteca matplotlib, é necessário importá-la usando:
import matplotlib.pyplot as plt
%matplotlib inline
O comando %matplotlib inline garante que os gráficos sejam mostrados corretamente.
Em geral, o código usado para gerar um plot segue o esquema:
- Plotar os dados:
plt.plot(x, y), onde x e y são listas e cada (x[i], y[i]) é um dos pontos plotados. Por exemplo, se Y = X², então y[i] = x[i]². - Configurar/estilizar os plots.
- Mostrar o plot na tela:
plt.show(). Em um notebook, geralmente esse passo pode ser omitido (o comandoplt.show()é rodado automaticamente no final de células que criam plots).